Review of Course Computer Vision Lecture 12:Visual Recognition
为期末考试复习做个准备。
Lecture 12: Visual Recognition
目标检测
目标检测的下游任务形式比较多,比如 Classification 或者 Searching 等。
这个任务可能会非常难,比如以下情况。

目标检测主要分成四种任务:
- 对图像或视频分类。
- 检测和定位目标。
- 语义分割和获取几何属性。
- 对人的行为和事件分类。
难点非常多,首先目标种类繁多,另一方面图片也可能随着各种变换 (光线,时间等) 而变换畸变,也会有遮挡和像上图一样的背景色融合,同一件物品也会有不同的形态。
KNN
KNN, K-nearest neighbor,处理的是对于一个点要找距离它第 $K$ 近的点。
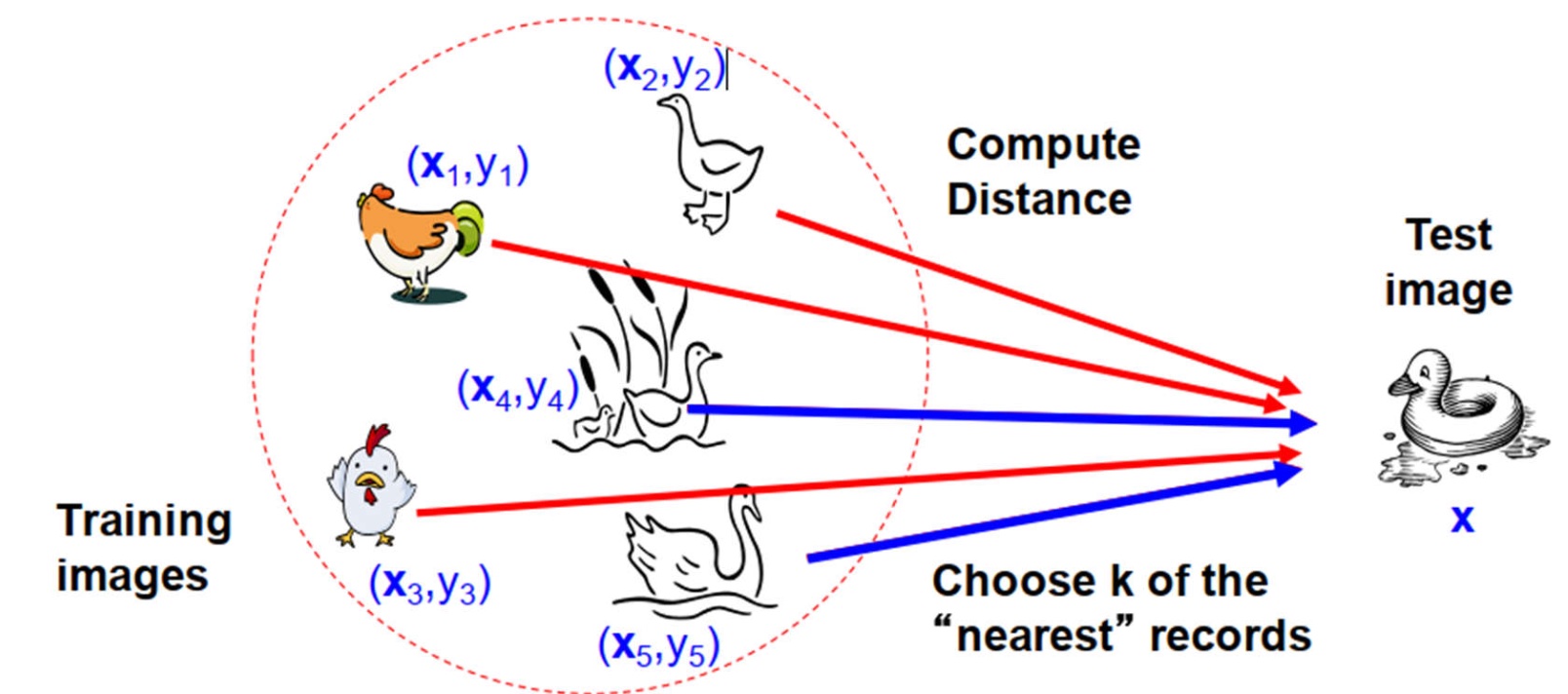
比如上图中,训练集中的 $\mathbf{x}$ 是该图像对应的向量,$y$ 是标签,对于询问的图像,求出对应的向量 $\mathbf{x}$,然后只需要找到前 $k$ 近的其它向量,就能大致知道询问的图像是哪一类了。
这里我们使用最为暴力的做法解决这个问题,对于每个 test 的图像,直接与所有 train 的图像求 $L_2$ 距离 (欧几里得距离),找出前 $k$ 近的图像,查询其中出现最多的标签是谁,那就认为 test 的这个图像的标签是谁。
但实际上 $k$ 并不好挑选,若 $k$ 太小,则会对噪声过于敏感;若太大,则很容易选择不正确的标签。
一般都是利用传统 ML 中的交叉验证法 (cross validation) 来选取 $k$ 值。
枚举每一个 $k$ 值,对于训练集,我们进行多次不同的划分,划分成一部分训练集,一部分验证集。对于每个验证集里的点,对着训练集进行正确性检验。最后选择平均表现最好的 $k$ 值作为实际应用的 $k$ 值。
另一方面,对对应的向量不做合适处理的话,容易出现一些反直觉的现象。

为此,我们对所有对应的向量归一化即可。
同时 KNN 会遇到维度灾难 (Curse of Dimensionality)。而且时间复杂度很糟糕,每次测试要遍历所有点,而训练时是 $\mathcal O(1)$。
KNN 的优势:简单而且有效。
劣势:
- 测试时暴力搜索的时间复杂度过高 (实际上可以使用 KDT 优化)。
- 空间复杂度也较高 (训练集需要一直存储)。
- 对高维数据不方便处理。
当然实际上有更多的做法,比如:

Bias and Variance
Variance (方差),指的是如果使用不同的训练数据,目标函数的估计值将更改的量。
低方差:预测目标函数的估计值随训练数据集的变化而略有变化。
高方差:随着训练数据集的变化,预测目标函数的估计值将发生较大变化。
低方差机器学习算法: 回归,线性判别分析和逻辑回归。
高方差机器学习算法: 决策树,k-邻近和支持向量机。
Bias (偏差),指的是模型所做的简化假设,以使目标函数更易于学习。
低偏差:预测目标函数使用的假设少。
高偏差:预测目标函数使用的假设多。
低偏差机器学习算法: 决策树,k-邻近和支持向量机。
高偏差机器学习算法: 线性回归,线性判别分析和逻辑回归。
Underfitting,欠拟合,一般是 high bias and low variance.
Overfitting, 过拟合,一般是 low bias and high variance.

选择机器学习算法前需要考虑:

A simple object recognition pipeline
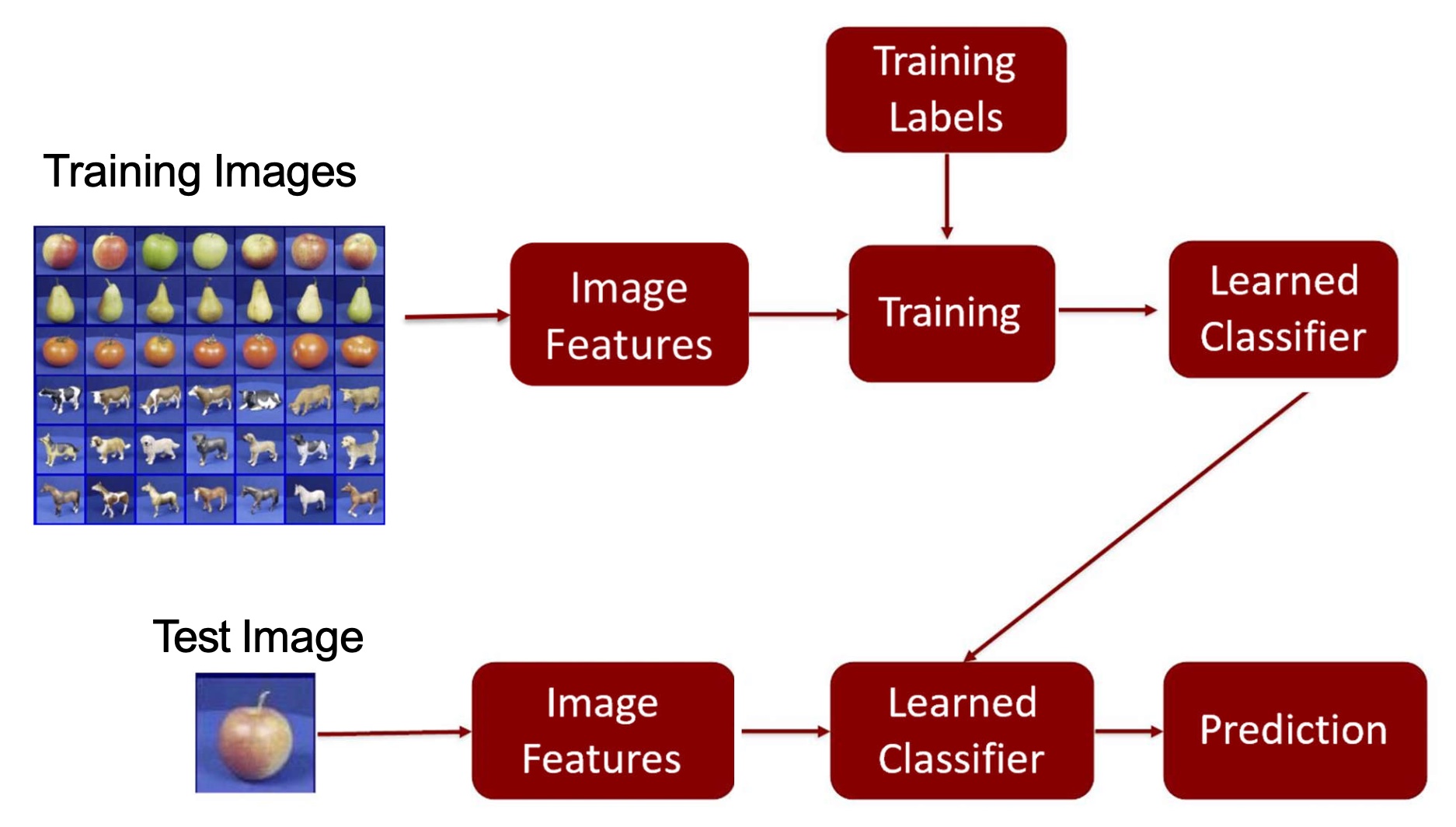

Visual bag of words: method
我们希望将一张图像分割成多个特征,每个特征有对应的单词,以此来描述这个图像。虽然实际上这是不考虑特征相对位置的办法,但基本上还是足够使用的。
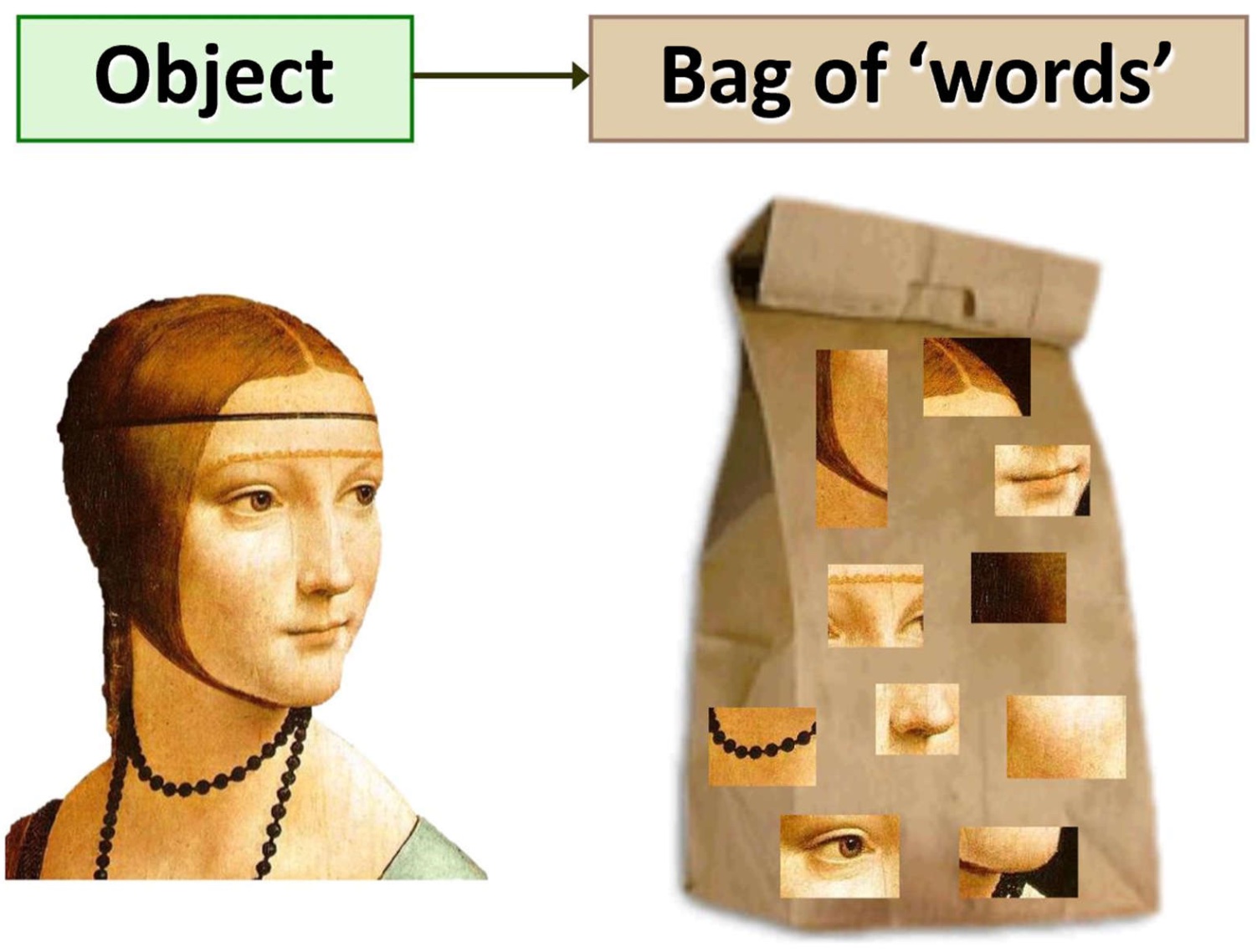
为此,我们先举一些例子,比如纹理识别。
Texture 都是由一些本原纹理 (textons) 组成的。

我们统计出图像的每个子部分的出现次数,便能知道这个纹理图像的基本分类情况了。

类似地,我们能对其它类型的图像也做类似的分割。

基于以上的思路,我们能得到一个基本的算法:对于图像集的每个图像,分别分离出它的特征,然后构建出一个特征字典。对于要查询的图像,我们分离出其的特征,并建出相关的直方图。对于满足直方图某些阈值条件的特征,我们往字典里搜寻最接近的特征。
具体步骤如下:
- 分离出特征。

- 构建可视化字典。

- 利用可视化字典量化特征。
- 对图像用特征的出现频率表达。
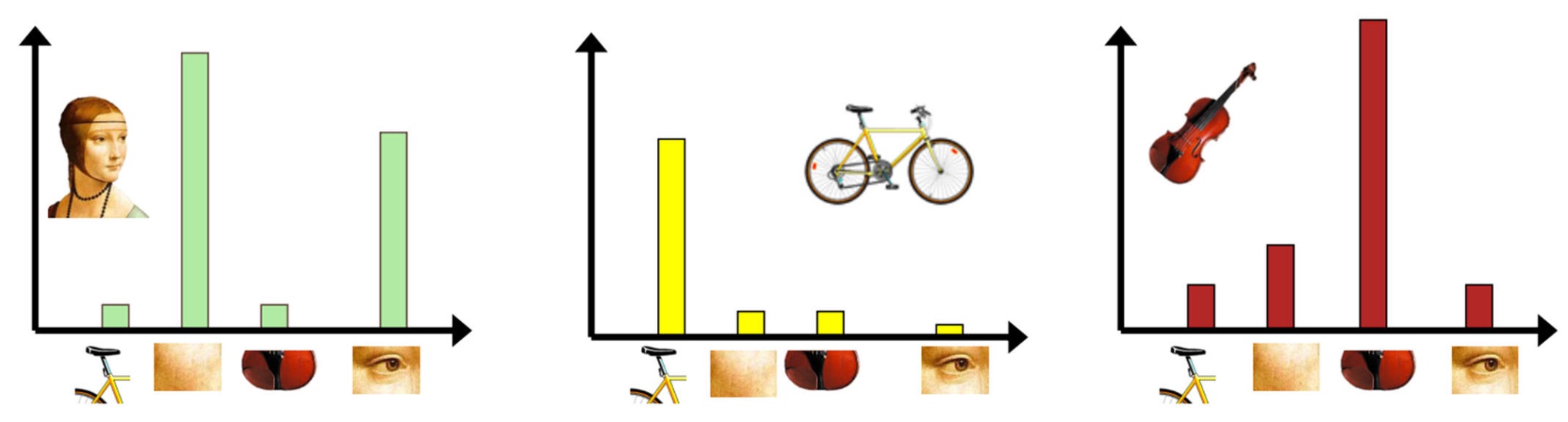
接下来我们将对每个步骤都进行一些讲解。
特征分离
这有多种方法,都将在这个 CV 复习中讲到。
比较传统的是网格法,把一个图像划分成若干个格子,检测格子内容。
还有经典的特征点提取,或者随机采样,以及语义分割等等。
构建可视化字典
构建可视化字典一般采用某种聚类算法。
我们将所有提取出的特征用向量表示,然后通过聚类获得分类,并且以此分类构建出了字典。

如何选择字典大小?一种是自动的聚类自行分割出了大小,另一种就是自行设定了字典大小。
自己设定的字典大小如果太小,则很难明确地表达所有特征;如果太大,容易过拟合。
有一种叫字典树的办法在计算上比较有效,具体内容这里不赘述。
量化特征
聚类方便了量化特征,我们直接选取类的中心作为该类的特征即可。这样的话,查询一个向量也只需找最近的向量即可。
图像表示
利用直方图求出的对应向量表达即可。方法有 TF-IDF, 加权 BOF 等。
Image classification
我们想用 bag of words 的办法做图像分类。
一个很基本的思路是使用 BoW 向量进行聚类,这样就能将图像划分成多类。test 的图像使用各种分类器判断归于哪一类即可。
这样的思路在做大规模的图像检索时效果会比较明显。
具体实现上,在处理完之前的那些信息后,会构建一张反向的映射表,即每个 word 在哪些图像中出现过。
这样我们在查询一个图像时,直接利用这张表快速检索到相关图像,然后做匹配。
重点: 实际上我们知道一个单词出现频率极大无比并不是好事,这反而说明这个单词不能称为特征。所以一般在求向量时会根据出现频率进行加权,即 TF-IDF 或加权 BOF 等方法。
这种检索办法的优势:
- 对 CD 封面,电影海报检索效果很好。
- 实时检索。
同时也可以对动作行为等进行检索。

另一方面,可以划分层次不同,多种划分方式合起来一起表达和检索,类似金字塔。